AWS S3 버킷 생성 후 파일 업로드/다운로드
이번 글에서는 AWS S3를 만들어보고 파일 업로드/다운로드 테스트를 진행할 것이다.
글의 순서는 다음과 같다.
- AWS S3란 무엇인가?
- AWS S3 버킷 만들기
- AWS S3 버킷에 파일 업로드/다운로드
1. AWS S3란 무엇인가?
S3란 Simple Storage Service의 약자로 AWS에서 제공하는 인터넷 저장소로 파일을 저장하는 용도로 사용되며 용량은 무제한이다. HTTP를 이용하여 파일 접근 및 업로드/다운로드가 가능하다. S3는 버킷(Bucket)과 객체(Object)로 구성된다.
버킷(Bucket) : S3에서 생성할 수 있는 최상위 디렉토리로, 각 리전(Region)별로 생성 가능하고 버킷의 모든 이름은 모든 S3 Region에서 유일해야 하며 계정별로 100개까지 생성할 수 있다. 또한 버킷 안에 객체(Object)가 저장되고 디렉토리 생성이 가능하며 저속 제어 및 권한 관리가 가능하다.
객체(Object) : S3에 데이터가 저장되는 최소단위로 파일과 메타데이터로 구성된다. 기본적으로 객체의 Key가 데이터 이름이고, Value가 데이터 타입이며, 객체 하나의 크기는 최소 1Byte부터 최대 4TB까지 가능하다.
1-1. S3를 사용하는 이유
SNS와 같이 서버에 많은 미디어 파일을 저장해야 하는 경우 EC2와 EBC만을 사용해서 저장을 하게 되면 용량에 따른 과금 및 저장소 구축/관리로 인한 성능 문제 등이 있을 수 있다. 하지만 S3를 사용하면 S3 한곳에 모든 미디어 파일을 관리할 수 있고 과금도 EC2 & EBS 조합보다 상대적으로 싼 가격에 이용할 수 있으며, AWS에서 스스로 S3 서버를 증설하고 성능을 관리하기 때문에 성능이나 용량을 높이는 기술력을 갖추지 않아도 된다.
만약 EC2와 EBS로 정적 웹서비스(HTML과 javascript로 구성된)을 구축한다면 일일이 EC2와 EBS를 생성할 필요없이 바로 S3에서 연결하여 사용하면 된다. 동적 웹페이지(ASP, JSP, PHP, Ruby on Rails등으로 구성된) 서비스를 한다면 동적 웹페이지의 처리는 EC2나 다른 곳에서 돌리고 나머지 정적 웹페이지 처리만 S3에서 처리하면 된다.
2. AWS S3 버킷 만들기
[콘솔에 로그인] -> [S3] -> [버킷 만들기]] 선택
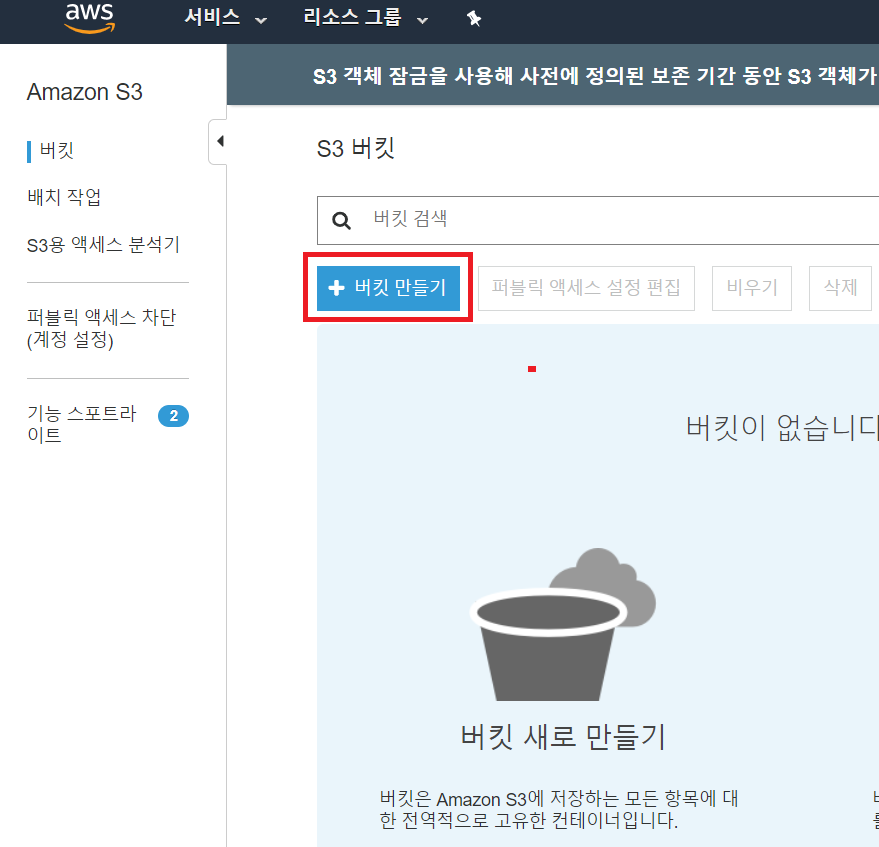
1. 이름 및 지역에서는 [버킷 이름]에 버킷 이름을 넣고 [리전]을 선택한다.
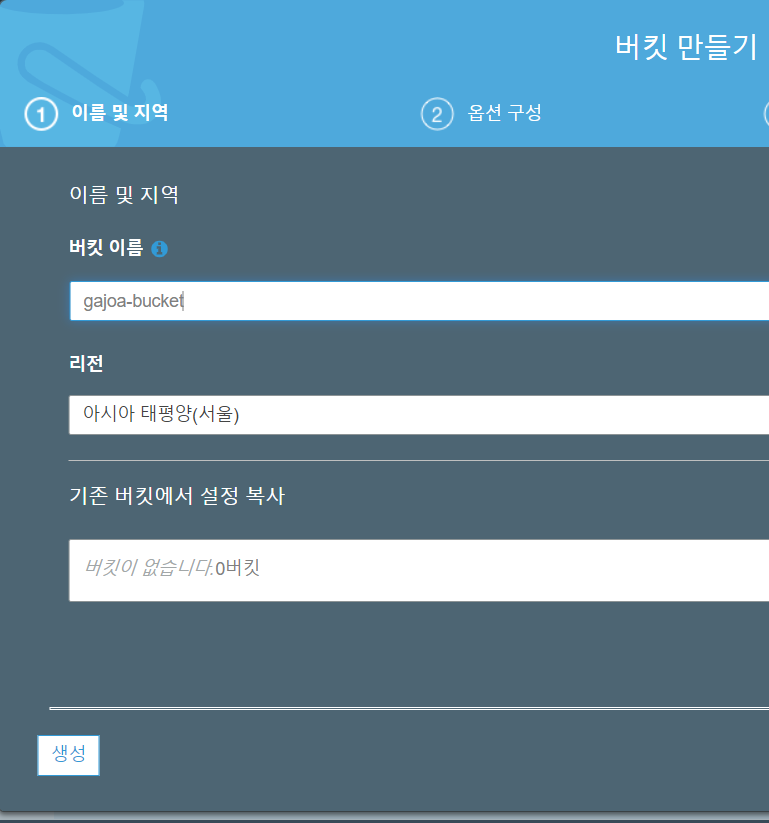
2. 옵션 구성에서는 [버전 관리], [서버 엑세스 로깅], [태그] 등을 선택할 수 있다. 버킷 생성 후에도 변경 가능하니 초기값 그대로 두고 [다음]으로 넘어간다.
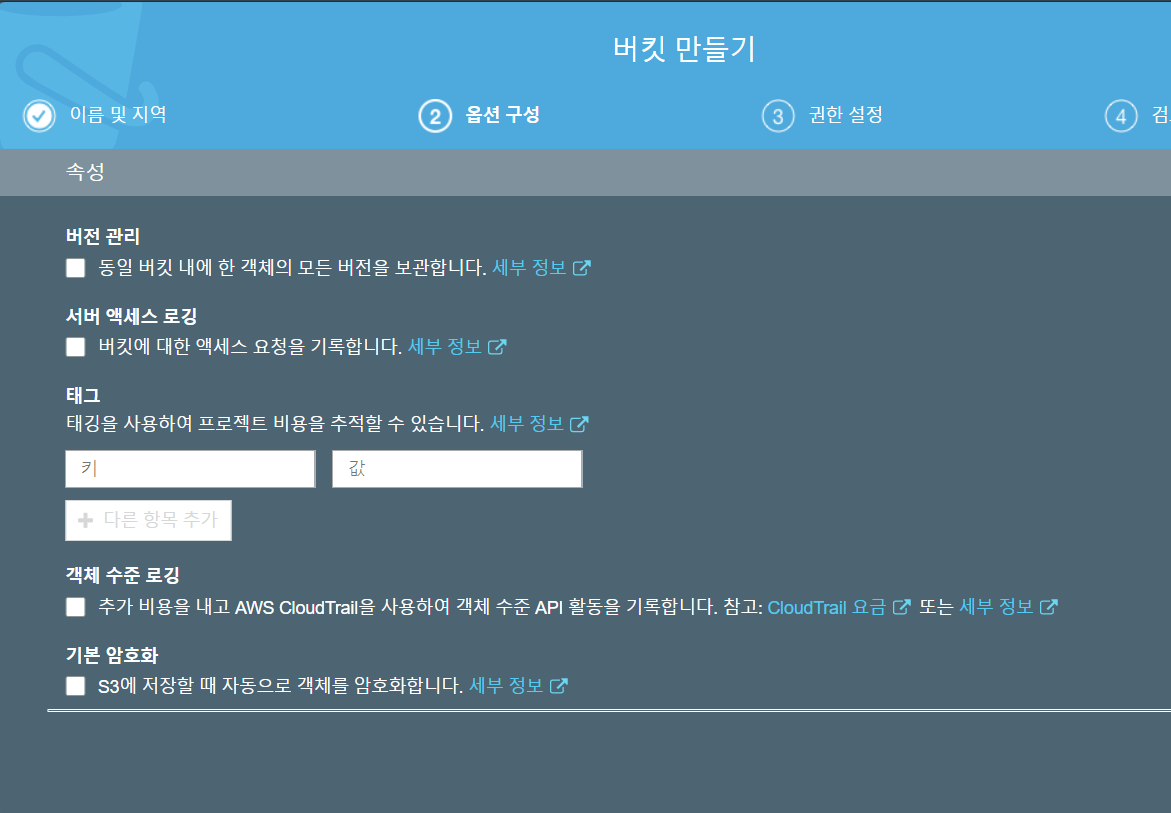
3. 권한 설정에서는 퍼블릭 엑세스 관련 설정이 가능하며 기본적으로 퍼블릭 엑세스 차단으로 설정되어 있다. 버킷 생성 후 변경 가능하니 초기값 그대로 두고 [다음]으로 넘어간다.
4. 검토에서 버킷 정보를 검토한 후 [버킷 만들기]를 클릭하면 버킷 생성이 완료된다. 완료된 버킷은 리스트에서 확인 가능하다.
3. AWS S3 버킷에 파일 업로드/다운로드
S3 버킷을 만들었으니 이제 파일 업로드/다운로드 테스트를 진행해보도록 하겠다.
3-1. AWS 콘솔을 통한 로컬PC파일 업로드/다운로드
버킷을 선택한 후 [업로드] -> [파일추가]를 선택한다.
로컬PC에서 파일을 선택한 후 [업로드] 버튼을 클릭하면 파일이 정상적으로 업로드가 된다.
파일 선택 후 [다운로드] 버튼을 클릭하면 정상적으로 다운로드가 된다.

3-2. EC2 인스턴스 내 파일 업로드/다운로드
다음으로 EC2에서 S3로 파일을 업로드/다운로드 해보도록 하겠다.
EC2에서 S3로 파일을 업로드 하려면 aws cli를 이용해야 하는데, EC2에 S3 접근 권한이 없다면 접근할 수 없다
따라서 만약 EC2 인스턴스 생성 시 S3에 접근 가능한 IAM역할을 부여하지 않았으면, S3 접근할 수 있는 IAM역할을 가진 사용자를 새로 생성한 다음, EC2 인스턴스에서 새로 생성한 사용자로 접근해야 한다(aws configure 명령어 사용). EC2 생성 시 S3 접근권한이 있는 IAM역할을 부여했다면 사용자는 만들지 않아도 된다.
AWS 홈페이지에서 [콘솔에 로그인] -> [IAM]을 선택한 후 [사용자] -> [사용자 추가]를 선택한다.
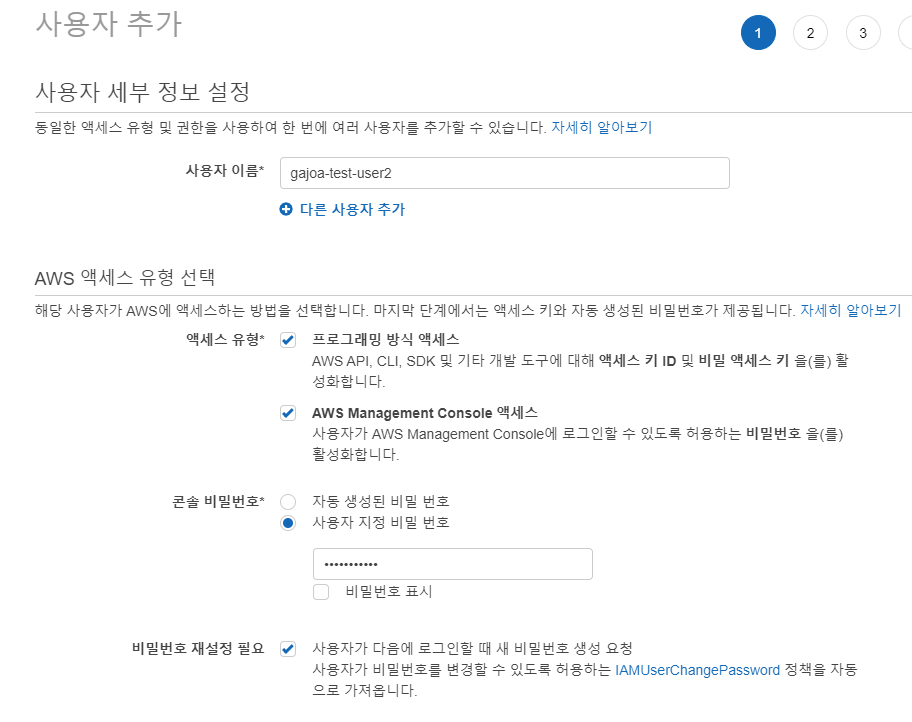
[사용자 세부 정보 설정] 및[ AWS 엑세스 유형]을 입력한다.
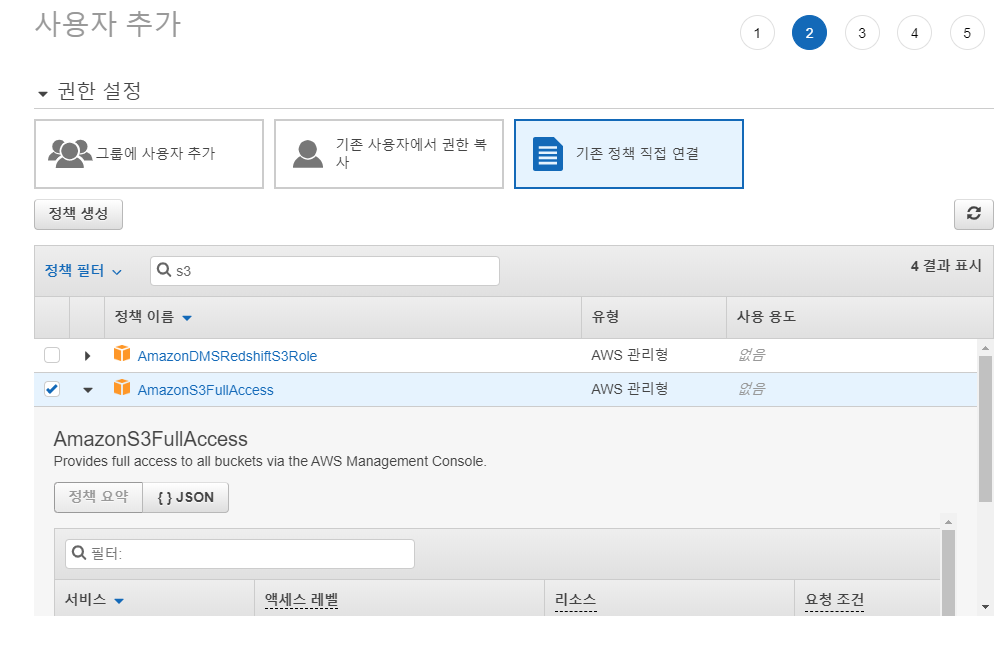
[권한 설정]에서 기존 정책 직접 연결을 선택한 후 [AmazonS3FullAccess]를 선택한다(버킷 생성 및 동기화 등 모든 작업을 진행할 것이므로)
[태그]와 [검토]는 그대로 넘어간 후 사용자를 추가한다. [엑세스 키 ID]와 [비밀 엑세스 키]는 추후 접속 시 필요하므로 따로 복사해 놓는다.
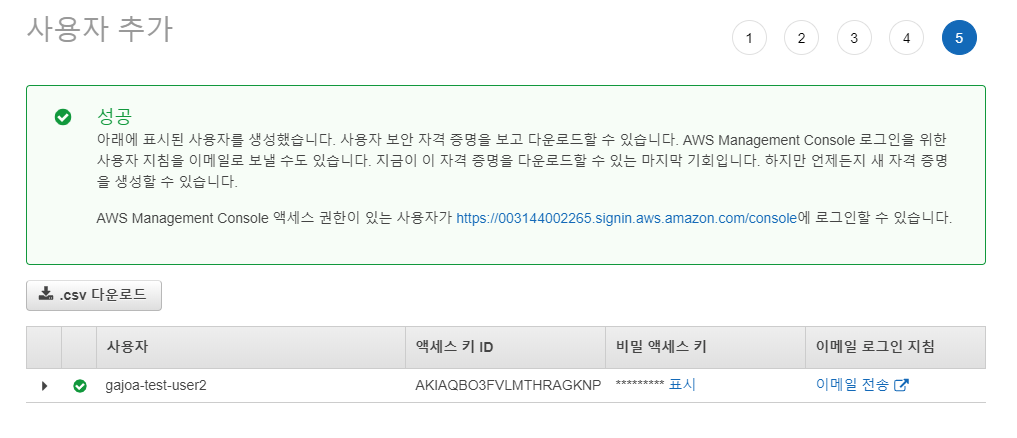
S3 Access 권한이 있는 IAM 사용자가 추가되었으면 EC2 인스턴스를 실행시킨다.
실행시킨 후 aws configure 명령어를 입력하여 cli 접속 정보를 설정한다.
# aws configure
AWS Access Key ID [None]: [엑세스 키 ID]
AWS Secret Access Key [None]: [비밀 엑세스 키]
Default region name [None]: ap-northeast-2
Default output format [None]: [공백 enter]
aws s3 명령어로 s3 내 버킷 리스트 및 파일 리스트를 확인한다.
# aws s3 ls # 내 계정의 s3 버킷 리스트
# aws s3 ls [버킷명] # 내 버킷 내 파일 리스트
aws s3 cp 명령어로 ec2 인스턴스 내 파일을 s3로 업로드한다.
# aws s3 cp [source파일명] s3://[destination버킷명]/[destination파일명]
만약 업로드하는 파일을 모두가 읽을 수 있도록 권한을 설정하려면 --acl public-read 옵션을 달아준다.
# aws s3 cp [source파일명] s3://[destination버킷명]/[destination파일명] --acl public-read
파일을 다운로드 하는 방법은 업로드하는 방법과 동일하다(source와 destination만 바꿔주면 된다)
# aws s3 cp s3://[source버킷명]/[source파일명] [destination파일명] 
참고
https://lovit.github.io/aws/2019/01/30/aws_s3_iam_awscli/
AWS CLI (Command Line Interface) 를 이용하여 S3 버킷 다루기 (파일 업로드, 폴더 동기화) 및 AWS IAM 등록
이전 포스트에서 AWS S3 에 버킷을 만들고 Web UI 를 이용하여 파일을 업로드, 공유하였습니다. 이번에는 AWS CLI 를 이용하여 로컬과 S3 bucket 을 동기화 시킵니다. CLI 는 terminal 환경에서 AWS 를 이용할 수 있도록 도와줍니다.
lovit.github.io
AWS CLI를 사용하여 ec2에서 s3로 업로드/다운로드 하기 (우분투 Ubuntu) - Algopie's Blog
awscli를 사용하여 ec2에서 s3로 업로드 다운로드 하는 방법을 소개합니다. aws s3 help 명령어로 강력한 헬프 기능을 사용 할 수 있습니다.
blog.algopie.com
https://interconnection.tistory.com/51
11-1. S3(Simple Storage Service)의 핵심 기능
S3(Simple Storage Service)는 인터넷 스토리지 서비스로, 용량은 무제한이고 파일을 저장하는 용도로 사용됩니다. 웹프로토콜인 HTTP 프로토콜로 파일에 접근할 수 있습니다. HTTP프로토콜을 이용해서 파일을 업..
interconnection.tistory.com