이번 글에서는 Zipkin과 Spring Cloud Sleuth를 활용하여 분산 환경(MSA 환경)에서 트랜젝션 로그 트레이싱을 하는 방법에 대해서 배워보도록 하자.
이 글의 순서는 다음과 같다.
1. Zipkin & Spring Cloud Sleuth란 무엇인가?
2. Zipkin 실행하기
3. Spring Boot2 서비스에 Zipkin & Spring Cloud Sleuth 적용
4. 테스트
1. Zipkin & Spring Cloud Sleuth란 무엇인가?
1-1. Zipkin이란?
마이크로서비스아키텍쳐(MSA) 환경에서는 하나의 서비스 호출을 통해 내부적으로 여러개의 서비스가 호출될 수 있다. 그렇기 때문에 특정 구간에서 병목이 생길 경우 전통적인 모니터링 방식인 APM(Application Performance Monitoring, 예를 들면 Jennifer) 도구를 이용해서는 추적이 어렵다. 그렇기 때문에 별도의 분산 환경 로그 트레이싱 시스템이 필요하게 되었다.
Zipkin은 분산 환경에서 로그 트레이싱하는 오픈소스로 트위터에서 개발되었으며, 현재 가장 활성화된 오픈소스다(오픈 소스 생태계가 활발하여 플러그인이나 부가적인 도구가 많다). Zipkin으로 추적할 수 있는 분산 트랜잭션은 HTTP, gRPC가 있다.
1-2. Zipkin 구조도(흐름도)

1-3. Zipkin 구성요소
Zipkin은 크게 Zipkin Client Library와 Zipkin Server로 구성되며, Zipkin Server는 Collector, Storage, API(Query Service), Web UI(Dashboard)로 구성된다.
1. Zipkin Client Library : 서비스에서 트레이스 정보를 수집하여 Zipkin Server의 Collector 모듈로 전송하며, 지원하는 언어는 Java, Javascript, Go, C# 등이 있다. Collector로 전송할 때는 다양한 프로토콜을 사용할 수 있지만 일반적으로 HTTP를 사용하고, 시스템이 클 경우 Kafka 큐를 통해서도 전송을 한다.
2. Collector : Zipkin Client Library로부터 전달된 트레이스 정보 유효성을 검증하고 검색 가능하게 저장 및 색인화 한다.
3. Storage : Zkipkin Collector로 보내진 트레이스 정보는 Storage에 저장된다. Zipkin은 초창기에는 Cassandra에 데이터를 저장하도록 만들어졌지만(Cassandra가 확장 가능하고 유연한 스키마를 가지고 있기 때문에 Twitter 내에서 많이 사용되었음), 그 뒤로 ElasticSearch나 MySQL도 지원 가능하게 구성되었다. 그 외에 In-Memory도 지원 가능하기 때문에 간단히 로컬에서 테스트할 때는 In-Memory, 소규모는 MySQL, 운영환경에 적용은 Cassandra나 ElasticSearch를 저장소로 사용하는 것이 좋다.
4. API(Zipkin Query Service) : 저장되고 색인화된 트레이스 정보를 검색하기 위한 JSON API이며, 주로 Web UI에서 호출된다.
5. Web UI : 수집된 트레이스 정보를 확인할 수 있는 GUI로 만들어진 대쉬보드이며, 서비스 / 시간 / 어노테이션 기반으로 데이터 확인이 가능하다. Zipkin 서버의 대쉬보드를 사용할 수도 있고, ElasticSearch 백앤드를 이용한 경우는 Kibana 활용도 가능하다.
1-4. Spring Cloud Sleuth란?
MSA환경에서 클라이언트의 호출은 내부적으로 여러 마이크로서비스를 거쳐서 일어나기 때문에 추적이 어렵다. 때문에 이를 추적하기 위해서는 연관된 ID가 필요한데, 이런 ID를 자동으로 생성해주는 것이 Spring Cloud Sleuth이다.
Spring Cloud Sleuth는 Spring에서 공식적으로 지원하는 Zipkin Client Library로 Spring과의 연동이 매우 쉬우며, 호출되는 서비스에 Trace(추적) ID와 Span(구간) ID를 부여한다. Trace ID는 클라이언트 호출의 시작부터 끝날때까지 동일한 ID로 처리되며, Span ID는 마이크로서비스당 1개의 ID가 부여된다. 이 두 ID를 활용하면 클라이언트 호출을 쉽게 추적할 수 있다.

2. Zipkin 실행하기
그럼 이제 Zipkin을 실행시켜보자
Zipkin 실행 방법은 https://zipkin.io/pages/quickstart.html 를 참고하면 되며, 필자는 Jar 파일로 Zipkin을 실행해 보았다. Zipkin이 실행되기 위해서는 서버에 JDK 8 이상이 설치되어 있어야 한다.
Zipkin 실행은 AWS EC2 Instanace(Amazon Linux 2)에서 진행했으며, JDK는 11버전을 사용했다.
Zipkin 다운로드 후 실행하기 :
ec2-user]$ curl -sSL https://zipkin.io/quickstart.sh | bash -s
ec2-user]$ java -jar zipkin.jar
Zipkin 이 실행되면 9411 포트에서 실행될 것이다.
다음으로 Zipkin의 UI Dashboard로 접속해보자. Zipkin UI Dashboard도 9411포트에서 실행되기 때문에, UI Dashboard에 접속을 하기 위해서는 우선 9411 포트 방화벽이 열려있어야 한다. EC2 Instance를 사용하고 있다면 인바운드 정책에서 9411포트를 등록하고, 일반 리눅스 서버를 사용한다면 9411포트 방화벽을 오픈하자.
방화벽이 오픈되었으면 다음으로 Zipkin의 UI Dashboard로 접속해보자. 접속 URL은 http://[Zipkin 실행 서버IP]:9411 로 접속하면 된다.

Zipkin UI Dashboard에는 접속이 되지만, Zipkin Client Library로부터 어떠한 정보도 받지 않았기 때문에 아무런 데이터도 나오지 않는다.
3. Spring Boot2 서비스에 Zipkin & Spring Cloud Sleuth 적용
이제 스프링부트로 구현한 마이크로서비스에 Zipkin Client Library를 적용하고 로그 정보를 수집해보자.
이 글에서 Zipkin Client Library를 적용할 스프링부트 서비스는 API Gateway, user-svc, cafe-svc 이렇게 총 3개의 서비스가 있다. 서비스 구현은 이전 블로그를 참고해서 구현해 보도록 하자(Spring Cloud Gateway를 활용한 API Gateway 구축).
이전 블로그처럼 서비스를 구현하기 어려우면 그냥 스프링부트 서비스 한개로만 테스트를 진행해도 된다(JDK11에 Gradle 6.4.1 버전 사용).
스프링부트 서비스가 구현되었으면, 각 스프링부트 서비스(api gateway, user-svc, cafe-svc)의 gradle.build 파일에 의존성을 추가해준 후 Reimport All Gradle Projects 를 통해 의존성에 추가된 라이브러리들을 다시 다운받는다.
build.gradle :
dependencies {
... // 기타 다른 라이브러리
compile group: 'org.springframework.cloud', name: 'spring-cloud-starter-zipkin', version: '2.2.3.RELEASE' // zipkin
compile group: 'org.springframework.cloud', name: 'spring-cloud-starter-sleuth', version: '2.2.3.RELEASE' // sleuth
}
다음으로 resources/application.yml에 zipkin과 sleuth 설정을 추가해준다.
application.yml :
spring:
application:
name: [Zipkin UI에서 확인하고 싶은 서비스명]
sleuth:
sampler:
probability: 1.0
zipkin:
base-url: http://[Zipkin 실행 호스트 ip]:9411/위 설정 중 probability에 들어간 값은 Zipkin에 트랜젝션을 어느정도의 비율로 보낼지에 대한 값이다. 기본값은 10%(0.1)이며, 1.0이면 트랜젝션을 100% 보내게 된다.
4. 테스트
설정이 완료되었으면, 게이트웨이와 마이크로서비스 2개를 실행시키자.
게이트웨이는 localhost:8080, 마이크로서비스는 localhost 8081과 8082에서 각각 실행시키자.
실행이 완료되었으면 포스트맨을 통해서 게이트웨이 URL로 서비스 요청을 날려보자. 이 글에서 사용한 마이크로서비스인 user-svc와 cafe-svc는 각각 /user/info, /cafe/info URI로 서비스가 실행 가능하므로, localhost:8080/user/info, localhost:8080/cafe/info로 서비스를 실행시켰다.
서비스를 실행시키면 호출된 게이트웨이와 마이크로서비스에 아래와 같이 로그가 남게 된다.
게이트웨이 로그 :

마이크로서비스로그 :

위 로그 내용 중 INFO절에 들어간 내용은 다음과 같다
- gateway/user-svc : 서비스명. application.yml에서 설정한 서비스명이며(spring.application.name), Zipkin에서도 해당 서비스명으로 로그 트레이싱이 가능하다.
- 0a91a3907ff49c93 : Trace Id
- 4585f9fd2384c777: Span Id. 게이트웨이 로그는 Trace Id와 Span Id가 동일하며, 게이트웨이에서 호출된 마이크로서비스 로그는 Trace Id와 Span Id가 서로 다르다.
- true : exportable. Zipkin으로 결과값을 전송했는지 여부이다. true인 경우 Zipkin Server로 로그값을 제대로 전송한 것이며, false인 경우는 전송하지 못한 것이다.
서비스가 정상적으로 호출 완료되었으면, 웹페이지에서 Zipkin UI Dashboard(http://[Zipkin 실행 호스트 ip]:9411) 로 접속해보면 로그 트레이싱 정보를 확인할 수 있다.
서비스 별 트레이싱 정보 :
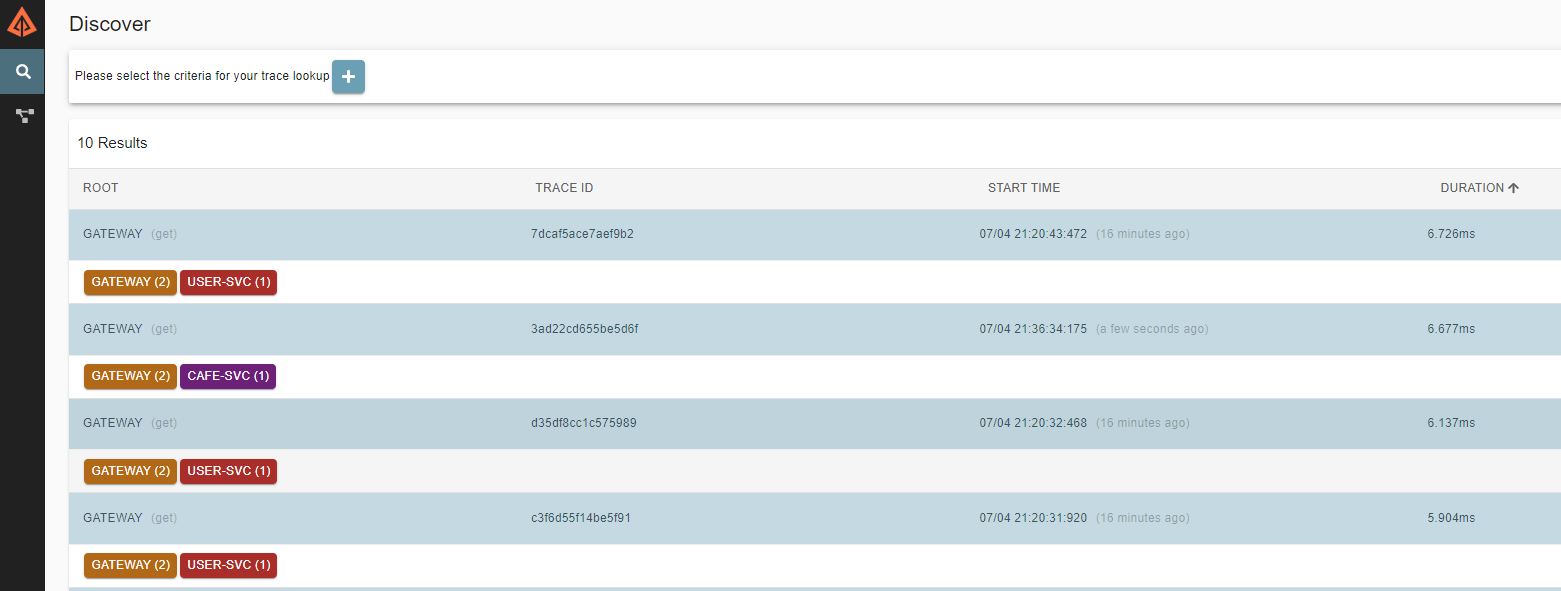
트레이싱 상세 정보 :

지금까지 Zipkin을 실행시켜 마이크로서비스들의 로그 트레이싱 정보를 스토리지(In-Memory)에 저장 후, 저장된 내용을 UI Dashboard를 통해서 확인하는 방법에 대해 알아보았다.
다음 장에서는 로그 트레이싱 정보를 In-Memory가 아닌 ElasticSearch에 저장 후, Kibana를 통해서 확인하는 방법에 대해 알아보도록 하자(https://twofootdog.tistory.com/66?category=903234)
참고
Zipkin을 이용한 MSA 환경에서 분산 트렌젝션의 추적 #1
Zipkin을 이용한 MSA 환경에서 분산 트렌젝션의 추적 #1 조대협 (http://bcho.tistory.com) 개념 분산 트렌젝션이랑 여러개의 서비스를 걸쳐서 이루어 지는 트렌젝션을 추적하는 기능을 정의한다. 마이크��
bcho.tistory.com
https://zipkin.io/pages/architecture.html
Architecture · OpenZipkin
Architecture Architecture Overview Tracers live in your applications and record timing and metadata about operations that took place. They often instrument libraries, so that their use is transparent to users. For example, an instrumented web server record
zipkin.io
https://sabarada.tistory.com/42
[MSA] MSA의 로깅과 트레이싱
안녕하세요. 오늘부터는 새로운 주제로 찾아뵙게 되었습니다. 바로 MSA입니다. 저희 회사에서 저는 요즘 프로젝트를 MSA의 기술들을 적용해가며 진행하고 있습니다. 오늘은 MSA의 기술 중 로그관��
sabarada.tistory.com
'IT > MSA' 카테고리의 다른 글
| 아파치 카프카(Apache Kafka) 정의 및 특징 (0) | 2020.10.17 |
|---|---|
| Jaeger를 활용한 분산 환경 서비스 로그 트레이싱(SpringBoot, Spring Cloud Gateway 활용) (1) | 2020.07.11 |
| Zipkin과 ElasticSearch, Kibana 연동하기 (1) | 2020.07.05 |
| Spring Cloud Gateway(SCG)를 활용한 API Gateway 구축 (7) | 2020.06.22 |
| Spring Cloud Gateway(SCG)에서 CORS 적용(allow-Credentials) (0) | 2020.05.27 |




댓글