이번 글에서는 AWS 쿠버네티스 클러스터를 모니터링하기 위해 EFK(Elasticsearch + Fluentd + Kibana) STACK을 구축해보도록 하겠다.
우선 Elasticsearch와 Kibana는 AWS EC2 인스턴스에 설치할 것이고(클러스터 구성이 아닌 단일 인스턴스에 구성할 것이다), Fluentd는 쿠버네티스 클러스터에 Pod로 띄워 로그를 수집하도록 하겠다.
만약 Fluentd와 Elasticsearch, Kibana를 모두 쿠버네티스 Pod로 띄우고 싶다면 다음 글을 참고하길 바란다(AWS EKS에서 로그 트레이싱 환경 구축하기(1) - EFK 스택 구성하기).
이번 글에서 구축하는 EFK STACK 구성도는 다음과 같다.

이 글은 다음과 같은 순서로 진행된다.
1. EFK(Elasticsearch + Fluentd + Kibana)란 무엇인가?
2. 실습 전 준비사항
3. ElasticSearch 설치하기
4. Kibana 설치하기
5. Fluentd 설치하기
6. Kibana로 Elasticsearch 데이터(로그) 확인
1. EFK(Elasticsearch + Fluentd + Kibana)란 무엇인가?
EFK란 Elasticsearch + Fluentd + Kibana의 조합을 일컫는다. 보통 Log처럼 지속적으로 누적되는 데이터를 실시간으로 분석할 때 많이 사용한다. 흔히들 알고 있는 ELK Stack은 ElasticSearch, Logstash, Kibana의 조합인데, Logstash 대신 Fluentd를 사용할 경우 EFK Stack이라고 부르기도 한다.
모니터링 시스템 구축 시 로그 수집기를 Logstash를 사용할지 Fluentd를 사용할지는 선택사항이지만, 필자가 EFK Stack 구축으로 글을 쓰는 이유는 Fluentd는 쿠버네티스와 같은 CNCF(Cloud Native Computing Foundation) Stack이라 요즘 마이크로서비스 모니터링 시스템 구축 시 많이 사용되기 때문이다.
EFK Stack에서 Elasticsearch, Fluentd, Kibana는 다음과 같은 역할을 수행한다.
1) Fluentd : 데이터(로그)를 수집해서 Elasticsearch로 전달
2) Elasticsearch : Fluentd로부터 받은 데이터를 검색 및 집계하여 필요한 정보 획득
3) Kibana : Elasticsearch의 빠른 검색능력을 통해 데이터 시각화 및 모니터링
1-1. Fluentd란?
Fluentd란 오픈소스 데이터(로그) 수집기이다. 보통 로그를 수집하는데 사용하지만, 다양한 데이터 소스(HTTP, TCP)로부터 데이터를 받아올 수 있다. Fluentd로 전달된 데이터는 tag, time, record(JSON) 로 구성된 이벤트로 처리되며, 원하는 형태로 가공되어 다양한 목적지(ElasticSearch, S3 등)로 전달될 수 있으며 Fail-Over를 위한 HA(High Availability) 구성도 가능하다.
Fluentd는 C와 Ruby로 개발되었으며, 더 적은 메모리를 사용하는 경량버전인 Fluent-Bit와 함께 사용할 수 있다(하지만 Fluent-Bit의 경우 HA 구성이 되지 않는다).
1-2. Elasticsearch란?
Elasticsearch는 아파치 루씬 기반의 확장성이 좋은 JAVA 오픈소스 분산 검색엔진이다. 많은 양의 데이터를 보관하고 실시간으로 저장, 검색, 분석할 수 있게 해준다.
Elasticsearch는 다음과 같은 특징을 가지고 있다.
1) 테이블과 스키마 대신에 문서 형식(JSON)으로 저장한다.
2) 쿼리 속도가 매우 빠르며 확장성이 뛰어나다
3) 에러에 대한 높은 탄성을 가지고 있으며 데이터 타입에 유연하다
4) 빅데이터를 처리할 때 매우 유리하다.
1-3. Kibana란?
Kibana는 Elasticsearch에서 색인된 데이터를 검색하고 시각화하는 오픈소스 도구이다. Elasticsearch의 데이터(로그)를 차트와 그래프 등을 활용하여 대쉬보드 형태로 시각화 할 수 있다.
2. 실습 전 준비사항
실습을 진행하기 위해서는 다음과 같은 준비가 되어 있어야 한다.
1. AWS내 쿠버네티스 클러스터 구축(필자는 kops를 활용하여 쿠버네티스 클러스터를 구축했다. https://twofootdog.tistory.com/43?category=868323 참고. 마스터노드 : t3a.small 1개, 워커노드 : t3a.small 1개)
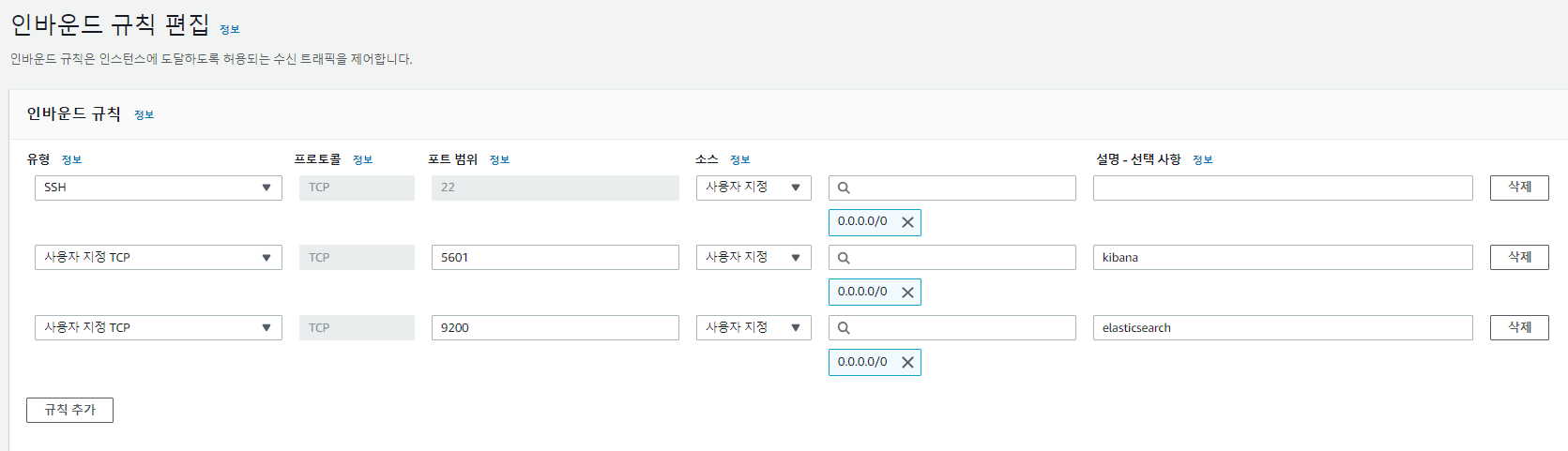
2. Elasticsearch + kibana 가 설치될 t3a.medium EC2 인스턴스(2 cpu, 4G memory) 생성 및 보안그룹 인바운드 규칙에 5601(kibana), 9200(elasticsearch) 포트 오픈
3. Elasticsearch 설치하기
우선 t3a.medium EC2 인스턴스에 Elasticsearch를 설치해보자. Elasticsearch를 설치하기 위해서는 JDK8 버전 이상이 설치되어 있어야 한다.
다음과 같이 설치 가능 JDK를 확인하고 설치해보자.
# sudo yum list *jdk*devel*
# sudo yum install -y java-1.8.0-openjdk-devel.x86_64
JDK 설치가 완료되었으면 Elasticsearch 설치를 설치한다.
# sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch # gpg 키 가져오기
# sudo vi /etc/yum.repos.d/elasticsearch.repo # repo를 아래 코드와 같이 작성
# sudo yum install -y --enablerepo=elasticsearch elasticsearch # elasticsearch 설치/etc/yum.repos.d/elasticsearch.repo :
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgchk=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
설치 후 Elasticsearch 설정파일을 수정한다.
# sudo vi /etc/elasticsearch/elasticsearch.yml/etc/elasticsearch/elasticsearch.yml :
...
cluster.name: my-application
...
node.name: node-1
...
network.host: 0.0.0.0
...
http.port: 9200
...
cluster.initial_master_nodes: node-1
...(https://esbook.kimjmin.net/02-install/2.3-elasticsearch/2.3.2-elasticsearch.yml 참고)
- cluster.name & node.name : 클러스터명과 노드명
- network.host : Elasticsearch에 접속을 허용할 ip. 0.0.0.0으로 작성할 경우 모든 접근을 허용한다는 뜻이다.
- http.port : Elasticsearch 서버에 접근할 수 있는 포트번호이며 기본값이 9200이다.
- cluster.initial_master_nodes : 클러스터의 초기 마스터 노드
그 외에는 기본값으로 둔다. Elasticsearch를 클러스터로도 구성할 수 있지만, 이 글에서는 그냥 단일 서버 구성으로 한다.

설정파일 수정이 완료되었으면 Elasticsearch 실행한 후 active상태인지 확인한다.
확인 후 Elasticsearch가 자동시작하게 시스템에 등록한다.
# sudo systemctl restart elasticsearch # 시작
# sudo systemctl status elasticsearch # 상태 확인
# sudo systemctl enable elasticsearch # 자동시작등록

netstat 명령어로 Elasticsearch의 9200(elasticsearch 포트), 9300(elasticsearch 노드간 통신 포트) 포트가 정상적으로 열렸는지 확인한다. curl로 Elasticsearch를 호출해보자.
# sudo netstat -anpt | grep 9200
# sudo netstat -anpt | grep 9300
# curl localhost:9200<netstat 옵션>
-a : 모든 네트워크 상태 출력(-all)
-n : 도메인 주소를 숫자로 출력(-numeric)
-p : PID(프로세서 ID)와 사용중인 프로그램명 출력(-program)
-t : TCP 프로토콜만 출력(-tcp)

4. Kibana 설치하기
Elasticsearch가 정상 실행되면 이제 t3a.medium EC2 인스턴스에 kibana를 설치해보자.
# sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch # gpg 키 가져오기
# sudo vi /etc/yum.repos.d/kibana.repo # repo를 아래 코드와 같이 작성
# sudo yum install -y kibana # kibana 설치/etc/yum.repos.d/kibana.repo :
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
설치 후 kibana 설정파일을 수정하자.
# sudo vi /etc/kibana/kibana.yml/etc/kibana/kibana.yml :
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "0.0.0.0"
...
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://localhost:9200"]
...(https://www.elastic.co/guide/en/kibana/current/settings.html 참고)
- server.port : kibana가 사용할 port
- server.host : kibana에 접속을 허용할 ip. 0.0.0.0으로 작성할 경우 모든 접근을 허용한다는 뜻이다.
- elasticsearch.hosts : elasticsearch 호스트가 사용하는 주소. 이 글에서는 동일한 호스트를 사용하고 있으므로 localhost를 사용함
설정파일 수정이 완료되었으면 kibana 실행한 후 active상태인지 확인한다.
확인 후 kibana가 자동시작하게 시스템에 등록한다.
# sudo systemctl restart kibana
# sudo systemctl status kibana
# sudo systemctl enable kibana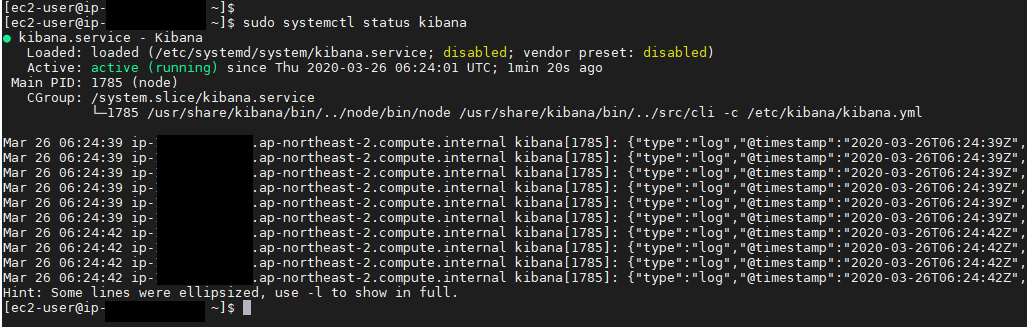
netstat 명령어로 kibana의 5601(kibana 포트)포트가 정상적으로 열렸는지 확인한다.
# sudo netstat -anpt | grep 5601
http://[Kibana가 설치된 호스트IP]:5601 주소로 웹브라우저를 실행시키면 kibana 웹페이지에 접속되는 것을 확인할 수 있다.

5. Fluentd 설치하기
다음으로 Fluentd를 설치하도록 하겠다.
Fluentd는 쿠버네티스 클러스터 내에 설치할 것이며, 작업은 쿠버네티스 클러스터와 연동된 EC2 인스턴스에서 진행할 것이다(이 글에서는 쿠버네티스 클러스터를 생성했던 t3a.nano 인스턴스에서 진행했다). 쿠버네티스 클러스터에 설치된 Fluentd는 쿠버네티스 클러스터 내에서 컨테이너 로그를 수집한 후 Elasticsearch로 전송할 것이다.
우선 Fluentd 메니페스트 파일(.yaml) 다운받자
# curl -LJ -o fluentd.yaml https://github.com/fluent/fluentd-kubernetes-daemonset/blob/master/fluentd-daemonset-elasticsearch-rbac.yaml?raw=true
그리고 다운받은 fluentd.yaml에서 FLUENT_ELASTICSEARCH_HOST 필드에 Elasticsearch가 설치된 EC2 인스턴스의 public ip를 입력한다.
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "[elasticsearch 호스트 ip]"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
그리고 해당 메니페스트파일을 쿠버네티스 클러스터에 등록하자
# kubectl apply -f fluentd.yaml
fluend pod가 정상 구동되어 로그가 수집되는지 확인하자.
# kubectl get pod --all-namespaces
# kubectl logs [fluend pod명] -n kube-system
6. Kibana로 Elasticsearch 데이터(로그) 확인
쿠버네티스 클러스터에 Fleuntd 설치가 완료되었다. 설치된 Fluentd는 쿠버네티스 클러스터에서 생성된 도커 컨테이너 로그를 수집한 후 Elasticsearch에 적재할 것이다. 이제 Kibana에서 Elasticsearch에 적재된 데이터(로그)를 확인해보자.
데이터(로그)를 확인하려면 Kibana에서 Elasticsearch에 적재된 데이터(로그)에 맞는 Index Patterns을 생성한 후 확인해야 한다.
Index Patterns를 생성한 후 데이터(로그)를 확인해보자. 우선 http://[Kibana가 설치된 호스트IP]:5601 로 접속한 후 [Management] -> [Kibana] -> [Index Patterns] -> [Create index pattern]을 선택한다.

Index pattern에 logstash-*를 입력한 후 [Next step]을 누른다.
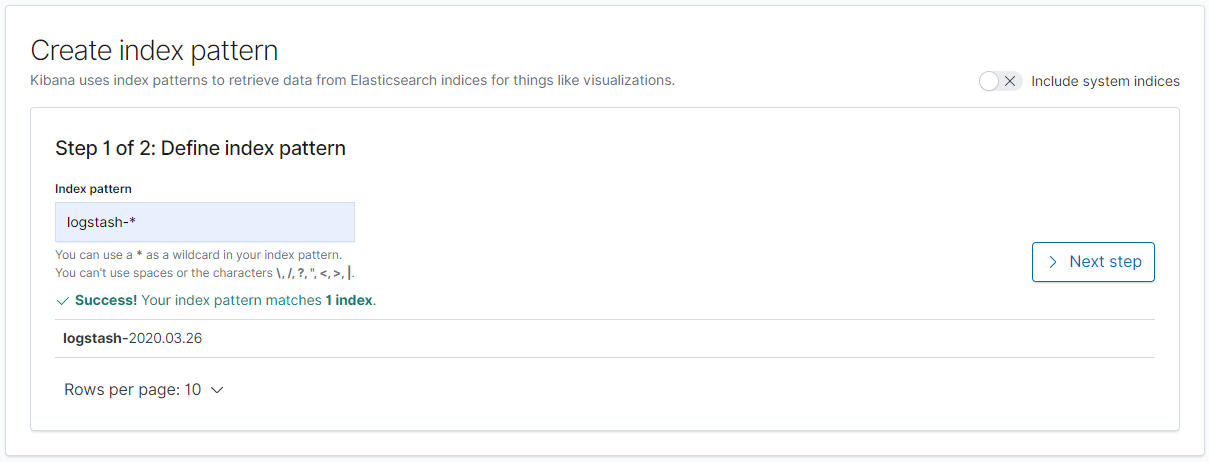
Time Filter field name은 @timestamp를 선택한 후 [Create index pattern]을 누른다.

Index Pattern이 생성된 후 좌측 네비게이션 바에 있는 [Discover]를 선택하면 적재되는 컨테이너 로그를 확인할 수 있다. 성공!!!
※ 시스템 리소스 사용량 체크
이 글 주제와는 별개로 Elasticsearch + Kibana가 설치된 t3a.medium(2cpu, 4G mem)의 리소스 사용량 현황을 확인해보면 CPU는 넉넉한 것으로 보이나 메모리는 꽤 빡빡하게 쓰고 있는 것 같다. 현재 수집 대상인 쿠버네티스 클러스터 내에 구동중인 서비스(스프링부트같은?)는 없는 상황이며 오로지 쿠버네티스 컨테이너 로그만 수집하고 있다. 만약에 서비스까지 구동되어서 서비스로그까지 수집하게 된다면 4G 메모리로는 부족할 것으로 보인다.
%Cpu(s): 0.8 us, 0.0 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3990216 total, 147500 free, 2029544 used, 1813172 buff/cache 
참고
[ELK Stack] Elastic(ELK) Stack 구축하기(Beat, Logstash, ElasticSearch, Kibana)
[ELK Stack] Elastic(ELK) Stack 구축하기(Beat, Logstash, ElasticSearch, Kibana) Elastic(ELK) Stack이란? 사용자가 서버로부터 원하는 모든 데이터를 가져와서 실시간으로 해당 데이터에 대한 검색, 분석 및..
ossian.tistory.com
http://www.iorchard.net/2019/06/10/installation_efk.html
installation EFK — iOrchard
June 10, 2019 installation EFK 개요 EFK 조합을 구성하여 작동 방식을 알아보자. E : Elastic search F : Fluentd K : kibana Fluentd? Fluentd란 오픈소스 데이터 수집기이다. Fluentd는 유연성을 위해 Ruby로 작성되었으며, 성능에 민감한 부분은 C로 작성되었다. Fluentd 프로젝트는 Treasure Data 에서 후원한다. 참 감사하다. 라이센스는 아파치 라이선스 2.0 이다.
www.iorchard.net
https://arisu1000.tistory.com/27852
쿠버네티스 로깅(kubernetes logging)
클러스터 환경에서 앱을 운영할때 주의해야할 것 중에 하나가 로그를 처리하는 것입니다. 컨테이너 오케스트레이터를 사용하는 환경에서 로그를 수집해야할 때 주의해야 할 점 중에 하나는 로그를 로컬디스크에 파..
arisu1000.tistory.com
https://jonnung.dev/system/2018/04/06/fluentd-log-collector-part1/
조은우 개발 블로그
jonnung.dev
https://victorydntmd.tistory.com/308
[Elasticsearch] 기본 개념잡기
1. Elasticsearch란? Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진입니다. Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이..
victorydntmd.tistory.com
https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
Install Elasticsearch with RPM | Elasticsearch Reference [7.6] | Elastic
On systemd-based distributions, the installation scripts will attempt to set kernel parameters (e.g., vm.max_map_count); you can skip this by masking the systemd-sysctl.service unit.
www.elastic.co
https://www.elastic.co/guide/en/kibana/7.6/rpm.html#rpm-repo
Install Kibana with RPM | Kibana Guide [7.6] | Elastic
An alternative package, kibana-oss, which contains only features that are available under the Apache 2.0 license is also available. To install it, use the following baseurl in your kibana.repo file: baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum
www.elastic.co
https://docs.fluentd.org/v/0.12/articles/kubernetes-fluentd
Kubernetes Fluentd
docs.fluentd.org
'IT > AWS' 카테고리의 다른 글
| AWS EKS를 활용한 쿠버네티스 클러스터 구축 (0) | 2020.08.06 |
|---|---|
| AWS RDS MariaDB 한글 깨짐 현상 해결(character_set, collation) (1) | 2020.04.12 |
| AWS CodePipeline에 Slack 알람 적용(Lambda, CloudWatch Events 연동) (0) | 2020.03.18 |
| AWS kops 쿠버네티스 클러스터에 Ingress 적용하기 (0) | 2020.03.08 |
| AWS kops 쿠버네티스 클러스터에 CI/CD 파이프라인(Pipeline) 만들기(CodeCommit, CodeBuild 활용) (0) | 2020.03.06 |




댓글