이번 글에서는 리눅스에 아파치 카프카(Apache Kafka)를 설치한 후 주키퍼와 연결해 볼 것이다.
이 글의 순서는 다음과 같다.
1. 사전준비
2. 아파치 카프카 설치
3. 아파치 카프카 실행/종료
4. Systemd에 카프카 등록(선택사항)
5. 주키퍼 연결 확인
1. 사전준비
이 글을 진행하기 전에는 다음과 같은 준비가 되어 있어야 한다.
1) 리눅스에 코디네이션 애플리케이션인 주키퍼 설치(리눅스에 주키퍼 설치하기 글 참고)
2) 아파치 카프카 클러스터를 구성할 리눅스 서버. 이 글에서는 AWS EC2 인스턴스(Amazon Linux 2 AMI (HVM) t2.smaull. cpu 1, memory 2G) 2대에 설치를 진행할 것이다(카프카 실행 시 1G 메모리로는 메모리 부족 에러가 발생한다)
2. 아파치 카프카 설치
사전 준비가 완료되었으면 아파치 카프카 설치를 진행해보자.
과방수 방식으로 운영되어 홀수개의 서버를 구성해야 하는 주키퍼와는 다르게, 카프카 클러스터는 홀수 운영을 하지 않아도 된다. 이 글에서는 2대의 리눅스 서버에 카프카 클러스터를 구성할 것이다. 또한 주키퍼 서버와 다른 별도의 서버에 카프카 설치를 진행할 것이다.
2.1. 서버 호스트네임 변경
우선 카프카를 설치하기 전에 root 계정이 아닌 경우 root계정으로 접속하자
$ sudo passwd root
$ su
다음으로 실습 편의를 위해 2개의 카프카 서버에 접속하여 서버 호스트네임을 변경해주자.
호스트네임은 kafka01, kafka02 로 변경할 것이다.
$ hostnamectl set-hostname kafka01
2.2. JDK 설치
주키퍼와 마찬가지로 카프카도 자바 애플리케이션이다. 때문에 준비한 서버에 자바가 설치되어 있어야 한다.
$ yum list *openjdk* #openjdk 리스트 확인
$ yum -y install java-1.8.0-openjdk.x86_64
2.3. 카프카 다운로드&설치
다음으로 카프카를 다운받도록 하자. 카프카 다운로드는 카프카 홈페이지에서 진행하면 된다(kafka.apache.org/downloads)
카프카 다운로드 페이지에서 원하는 카프카 버전을 선택한다.
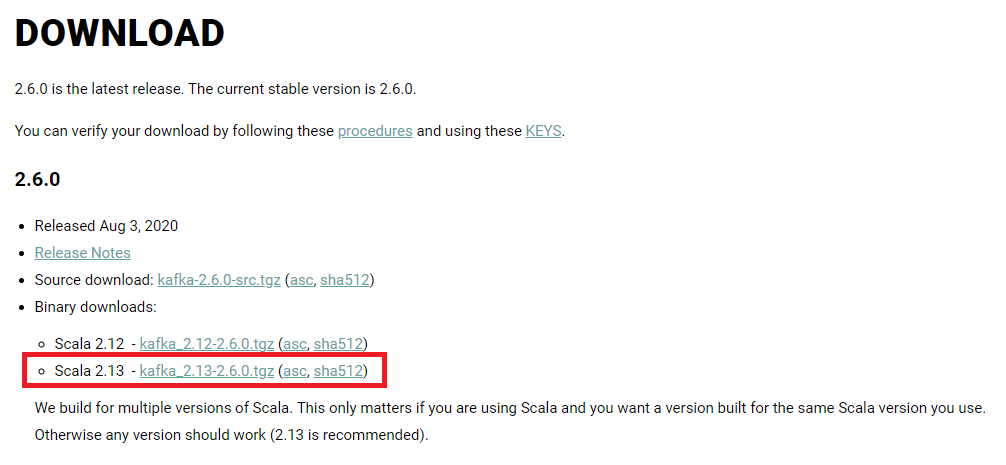
그 다음 다운로드 파일의 HTTP 경로를 확인한 후 wget 을 통해서 다운로드 받으면 된다.
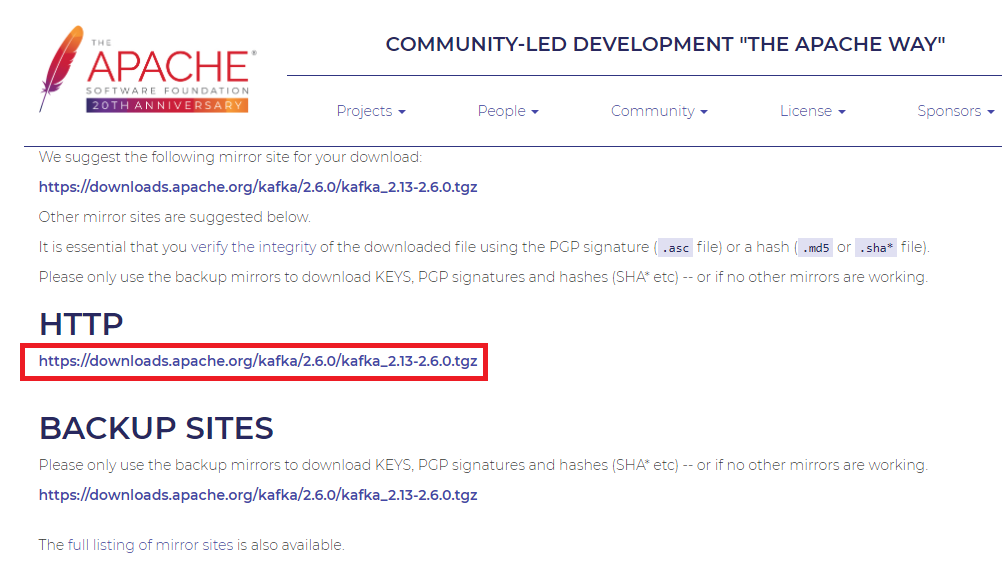
$ cd /usr/local
$ wget https://downloads.apache.org/kafka/2.6.0/kafka_2.13-2.6.0.tgz
다운이 완료되었으면 압축을 풀어주자
$ tar xvf kafka_2.13-2.6.0.tgz
압축을 풀었으면 주키퍼와 마찬가지로 접근하기 편하게 심볼릭 링크를 생성하자.
$ ln -s kafka_2.13-2.6.0 kafka
2.4. 카프카 환경설정
환경설정을 하기 전에 우선 카프카 저장 디렉토리를 생성해주자. 카프카는 일반 메시지 큐 서비스들과 달리 컨슈머가 메시지를 가져가더라도 저장된 데이터를 임시로 보관하는 기능이 있으며, 하나 혹은 여러 디렉토리를 구성하여 보관 가능하다(디스크가 여러개인 서버의 경우는 디스크 수만큼 디렉토리를 만들어주면 디스크별로 I/O 분산이 가능하다). 이 글에서는 디렉토리를 각 서버당 두 개씩 만들어주겠다(/data1, /data2로 만들어보자)
$ mkdir -p /data1
$ mkdir -p /data2
다음으로 카프카 환경설정 파일을 열어보자
카프카 환경설정은 카프카설치디렉토리/config/server.properties에서 한다.
$ vi /usr/local/kafka/config/server.properties############################# Server Basics #############################
broker.id=0
...
############################# Log Basics #############################
log.dirs=/tmp/kafka-logs
...
############################# Zookeeper #############################
zookeeper.connect=localhost:2181
...
컨피그 파일을 연 후 파일을 수정해주자.
1) broker.id : 브로커를 구분하는 아이디다. 이 글에서는 카프카 브로커 아이디를 호스트 명에 맞게 숫자로 지정해주겠다(호스트명이 kafka01인 경우는 broker.id를 1로, kafka02인 경우는 broker.id를 2로 지정)
2) log.dir : 로그가 저장되는 위치다. 조금 전 생성했던 카프카 저장 디렉토리인 /data1, /data2를 입력해준다.
3) zookeeper.connect : 주키퍼 접속 정보다. 주키퍼 앙상블에 해당하는 호스트명:포트번호를 입력한다. 그런데 그냥 호스트명:포트번호만 입력하면, 여러 개의 카프카에서 주키퍼에 접근하여 지노드를 사용할 때 동일한 지노드를 사용하게 되어 충돌이 발생할 수 있으므로, 호스트명:포트번호 뒤에 지노드 이름을 추가로 입력해야 한다(이 글에서는 지노드 이름을 카프카 호스트명 + _znode 로 입력할 것이다)
kafka01서버 : zookeeper.connect=zk01:2181,zk02:2181,zk03:2181/kafka01_znode
kafka02서버 : zookeeper.connect=zk01:2181,zk02:2181,zk03:2181/kafka02_znode
수정이 완료되면 다음과 같다(kafka01 호스트 기준이다)
############################# Server Basics #############################
broker.id=1
...
############################# Log Basics #############################
log.dirs=/data1,/data2
...
############################# Zookeeper #############################
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181/kafka01_znode
그 외에도 환경설정 파일에는 설정할 수 있는 여러 옵션이 있다.
- delete.topic.enable : 토픽 삭제 기능을 ON/OFF (enable = 토픽 삭제 가능)
- default.replication.factor : 리플리케이션 팩터(Replication Factor) 옵션을 주지 않았을 경우의 기본값
- min.insync.replicas : 최소 리플리케이션 팩터
- auto.create.topic.enable : 존재하지 않는 토픽으로 퍼블리셔가 메시지를 보냈을 때 자동으로 토픽 생성
- log.retention.hours : 저장된 로그의 보관 주기
- compression.type : 토픽의 최종 압축 형태. gzip, snappy, lz4 등의 표준 압축 포맷 지원
- zookeeper.session.timeout.ms : 브로커와 주키퍼 사이의 최대 연결 대기 시간. 해당 시간동안 주키퍼와 연결되지 않으면 타임아웃
- message.max.bytes : 카프카에서 허용되는 가장 큰 메시지 크기
좀 더 자세한 환결설정 정보는 아파치 카프카 웹페이지에서 확인하자(kafka.apache.org/documentation/#brokerconfigs)
3. 아파치 카프카 실행/종료
3.1. 카프카 실행하기
서버 2개에 카프카 설정이 완료되었으면 이제 2개의 서버에서 카프카를 실행해보자.
실행 명령어는 /usr/local/kafka/bin 에 있는 kafka-server-start.sh를 사용하면 된다(명령어를 사용하기 전에 주키퍼가 설치된 서버에서 주키퍼를 실행시키도록 하자)
$ /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
아래와 같이 정상적으로 실행되는 것을 확인할 수 있다(만약 카프카가 정상적으로 실행되지 않는다면 주키퍼가 정상적으로 실행되고 있는지, 그리고 주키퍼 클라이언트 포트가 정상적으로 오픈되어 있는지를 확인해 보도록 하자)

카프카를 실행시켰다면 카프카의 기본포트인 9092 포트가 열려있는지 확인해보자. LISTEN 상태이면 카프카가 정상적으로 실행중인 것이다.
$ netstat -ntlp | grep 9092
3.2. 카프카 백그라운드에서 실행하기
만약 카프카를 백그라운드에서 실행시키고 싶다면 명령어 뒤에 &를 추가하거나, --daemon 옵션을 주면 된다.
$ /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
혹은
$ /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
3.3. 카프카 종료
카프카를 종료시키는 방법은 kafka-server-stop.sh를 이용하면 된다.
$ /usr/local/kafka/bin/kafka-server-stop.sh
3.4. 카프카 로그 확인
카프카 로그는 카프카 설치 디렉토리/logs/server.log 파일에서 확인 가능하다.
4. Systemd에 카프카 등록(선택사항)
카프카도 주키퍼와 동일하게 운영 편의성 등을 위해 systemd에 등록할 수 있다.
우선 기존에 수행중인 카프카를 종료시킨 후, 카프카를 systemd에 등록하기 위해 카프카가 설치된 각 서버에 kafka-server.service 란 파일을 한개 만들어주도록 하자
$ vi /etc/systemd/system/kafka-server.service
/etc/systemd/system/kafka-server.service :
[Unit]
Description=kafka-server
After=network.target
[Service]
Type=simple
User=root
Group=root
SyslogIdentifier=kafka-server
WorkingDirectory=/usr/local/kafka
Restart=no
RestartSec=0s
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
systemd 파일을 새로 만들거나 기존 파일을 수정한 후에는 systemd 재시작을 위해 daemon-reload 명령어를 수행해야 한다.
$ systemctl daemon-reload
다음으로 systemd에 등록한 카프카를 systemctl start 명령어를 통해 실행해 보도록 하자.
$ systemctl start kafka-server.service
실행을 완료하였으면 systemctl status 명령어로 카프카 상태를 확인해보도록 하자.
$ systemctl status kafka-server.service
5. 주키퍼 연결 확인
이제 주키퍼와 카프카가 정상적으로 연결되었는지 확인해보도록 하자.
주피커 앙상블 중 서버 1대에 접속한 후 주키퍼 CLI로 접속해보자.
CLI에 접속하려면 아래와 같이 명령어를 수행하면 된다(zookeeper가 /usr/local/zookeeper/에 설치되어 있다는 가정이며, 주키퍼가 설치되지 않았다면 리눅스에 주키퍼 설치하기 참고 후 설치하도록 하자)
$ /usr/local/zookeeper/bin/zkCli.sh
이제 ls / 명령어를 이용하여 카프카 설정파일(카프카설치디렉토리/config/server.properties)에서 주키퍼 환경 설정 시 추가한 kafka01_znode, kafka02_znode 라는 지노드가 정상적으로 생성되었는지 확인해보자.
[zk: localhost:2181(CONNECTED) 0] ls /
다음으로 지노드 안에서 브로커 정보를 확인해보자. kafka01_znode의 브로커id는 1이고, kafka02_znode의 브로커id는 2다(카프카 환경설정에서 broker.id에 셋팅함)
zk: localhost:2181(CONNECTED) 21] ls /kafka01_znode/brokers/ids

마치며
이번 장에서는 카프카를 설치한 후 실행시켜 주키퍼와 연결되는 것 까지 실습해 보았다.
다음 장에서는 카프카의 기본적인 활용법에 대해 공부해 보겠다.
참고
- 카프카, 데이터 플랫폼의 최강자 - 고승범. 공용준 지음




댓글